Developing an AI-Powered Learning Experience for Opticians
An AI-powered learning platform that lets opticians practice patient conversations through guided role-play sessions, receive structured feedback on each consultation stage, and helps managers track learner progress across teams.
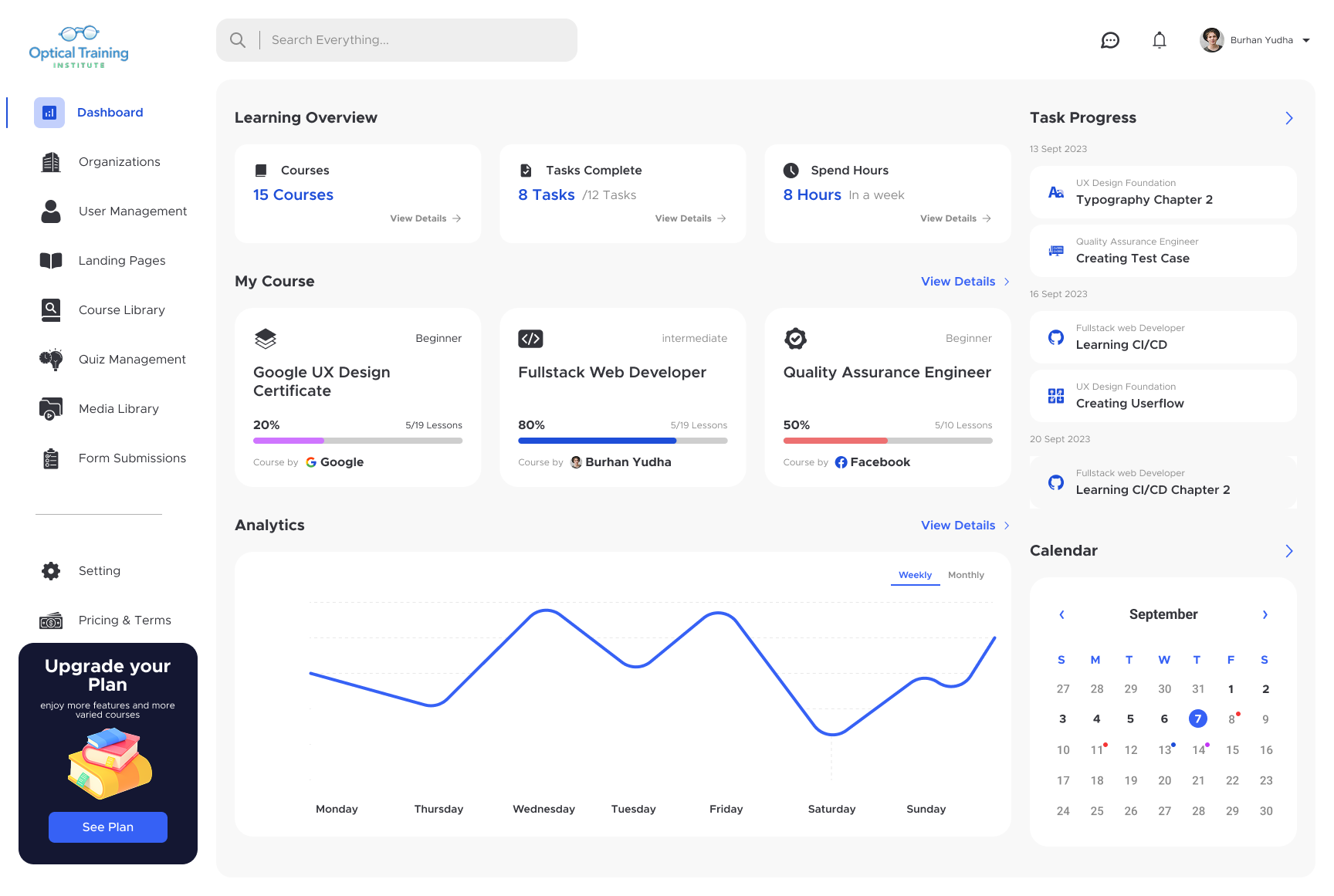
An AI role-play trainer for opticians
We developed an AI-powered learning platform that helps opticians improve their skills through courses, assessments, and guided practice.
Learners can join role-play sessions that act like real patient conversations. They practice greeting the patient, asking questions, understanding needs, recommending products, closing the discussion, and handling problems or complaints. The software offers several training scenarios and supports multiple practices, so larger firms can manage many learners from one place.
Detecting a learner's stage in live role-play
One of the biggest challenges was determining the learner's stage in a live role-play from the conversation itself without using a fixed script or manual tags. Conversations were open and free, so it was difficult to keep feedback and scores fair for all learners and cases, especially when learners jumped between steps or skipped key questions.
Choosing the right AI models was another issue. Using a large, expensive model for every step increased our running costs by about 30-50%, but using only small models could reduce the quality of feedback, especially on cases like handling complaints, budget limits, or prescription choices. Adding a two-way voice for both the "learner" and the "patient" was also difficult. If the delay exceeded 1-2 seconds during a live session, the conversation felt slow and unnatural, and learners were more likely to interrupt or repeat themselves.
On the system side, unstable internet connections sometimes caused the same message to be sent more than once. This created duplicate messages in the conversation history in about 2-5% of sessions, which could change the identified consultation stage and lead to repeated feedback. We also needed each scenario to feel realistic, with details such as prescription, budget, and daily needs, without making the dialogue feel scripted, repetitive, or identical across learners.
How we built it: Next.js, Clerk, and guided AI sessions
On the frontend, we used Next.js with Radix UI and shadcn to build a simple layout and reusable interface components. Clerk handled login and roles, making it easy to control access for different users and medical practices. Apollo Client connected the frontend to the backend using GraphQL, and TanStack React Table for assessments and learner progress.
On the backend, we used NestJS with GraphQL to build the main system. PostgreSQL and Prisma handled data storage and queries, while Redis improved performance by caching data. We used OpenAI models for role-play conversations and to detect which consultation stage the learner was in by classifying the dialogue into phases such as greeting, discovery, recommendation, and reaching 85-92% correct stage detection in common scenarios. A separate model was used to generate clear feedback using a defined scoring guide, enabling us to balance cost and quality.
ElevenLabs was used for AI audio, and we added voice streaming and buffering to keep two-way conversations smooth during live practice. We added message de-duplication with request IDs to prevent repeated submissions from creating duplicate entries in the conversation history, and lowered the duplicate rate from 2-5% of sessions to less than 1%. We used AWS services such as Lambda, S3, and SES, with Azure Blob Storage for files, emails, and other background tasks.
What we shipped: courses, assessments, and guided practice
Coding Crafts delivered a web-based learning platform with a clean UI, reliable backend, cloud support, and AI-powered training features. Opticians can now practice full patient conversations in real cases and receive clear, easy-to-apply feedback. The live coaching panel gives learners greater confidence when working with diverse patients and situations.
Before this platform, training was less interactive and harder to manage across teams. After launch, learners can handle full conversations in a defined way and receive clear feedback. Average role-play session time dropped from about 25 minutes to under 15 minutes because learners spend less time restarting or guessing the next step. Managers use assessment tools to track performance, and support inquiries dropped by around 20-30% after guided coaching and clear feedback were introduced, particularly questions related to "what to do next" and "how scoring works."
The outcome: patient conversations, practiced safely
This platform gave opticians a more practical and defined way to build their skills through digital learning, guided role-play, and performance-based assessments. It brings training, coaching, live practice, and evaluation together in one place. As a result, the learning experience is more interactive for learners and simpler for managers to track.
This case study shows how Coding Crafts develops modern web applications with clear learning flows, stable backends, cloud infrastructure, and AI-powered tools. It proves our ability to use advanced technology to solve training challenges in specialized industries while maintaining a fast, standardized, and measurable approach.
Let's build the next one.
Have a project like this? Tell us what you're building. A real person reads every message and replies within one business day.